
ssuperjun 님의 블로그
[스터디3] MySQL 스터디 발표자료 최종 본문
책 제목: 데이터베이스 시스템 개론과 MySQL 실습

2장: 데이터베이스 정의
데이터베이스는
- 통합 데이터: 중복 저장 방지 원칙
- 저장 데이터: 하드디스크나 메모리에 저장
- 운영 데이터: 조직의 운영에 필요한 데이터 집합
- 공용 데이터: 여러 사용자들이 공동으로 사용
특징
- 실시간 접근성: 질의부터 응답까지 짧은 시간
- 계속적인 변화: 삽입, 삭제, 갱신으로 데이터 변화
- 동시 공용: 동시 접근 처리 필요
- 내용에 의한 참조: 데이터 주소가 아닌, 내용 검색으로 데이터를 찾음
개체(entity), 속성(attribute) 예시
- 개체 = 학생
- 속성 = 학번, 성명, 전화번호
- 개체 인스턴스(어커런스) = 학생 한 명(하나의 row)
- 개체 집합 = 개체 인스턴스들의 집합
- 개체 타입 = 속성들의 집합
관계(relationship)
- 속성 관계: 속성들 간의 관계
- 개체 관계: 개체 집합 간 관계
교수 --지도--> 학생
4장: 데이터베이스 시스템
데이터베이스 시스템 구성 요소: 데이터베이스, DBMS, 데이터베이스 언어, 사용자, 관리자, 하드웨어

데이터베이스 언어
- 데이터 정의어: create, drop, alter 등
- 데이터 조작어: select, insert, update, delete
sql은 비절차적 데이터 조작어(처리 절차를 명시하지 않음)
- 데이터 제어어: grant, revoke
- 트랜잭션 제어어: commit, rollback, savepoint
데이터베이스 스키마: 데이터 구조와 제약조건 정의. 개체, 속성 및 관계에 대한 명세
- 외부 스키마: 사용자 입장에서 본 스키마
- 개념 스키마: 조직 전체 입장에서 본 스키마
- 내부 스키마: 물리적인 저장 구조

DBA 역할
- 개념 스키마 설계, 시스템 전반 운영 책임
- DB 관련 행정 업무: 사용자 요청 해결
- 모니터링, 통계 정보 분석
6장: 물리적 데이터 구조
하드디스크: 자성의 디스크를 고속으로 회전시키고 자기 헤드를 통해 데이터를 읽고 쓰는 외부 저장 장치. SSD보다 저렴하지만 속도가 느림
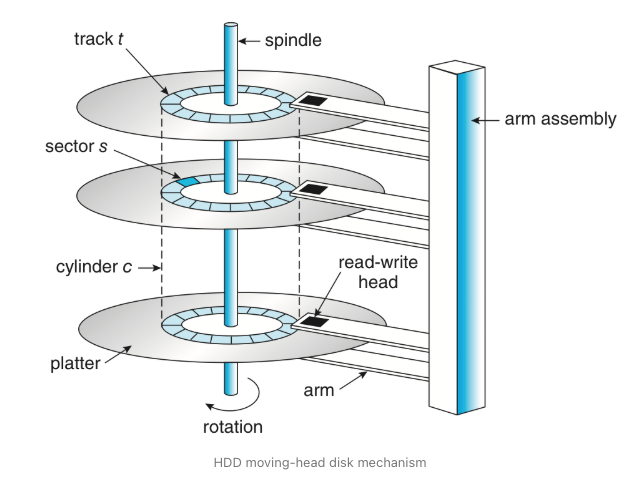
SSD: 반도체 소자 메모리를 저장 영역으로 사용하는 디스크. 빠르고 저전력이지만 하드디스크보다 비쌈
OS의 역할
- 버퍼링을 이용해 디스크 I/O 시 블록들을 한번에 많이 전송해 블록 전송 횟수를 줄이는 것이 성능 향상에 중요
- 메모리 내 데이터에 대한 캐시 미스(데이터가 메모리에 없으면 디스크에서 가져옴)를 방지하기 위해, LRU 등의 알고리즘을 사용
파일 조직 방법
순차 방법
- 엔트리 순차 파일: 레코드가 들어오는 순서대로 저장
- 키 순차 파일: 키값 순서대로 레코드 저장(쓰기가 오래 걸리지만 읽기가 빠름)
인덱스 방법
데이터 파일에 실제 데이터가 저장됐다면, 인덱스 파일을 통해 빠른 데이터 접근 가능
- 기본 인덱스: 인덱스를 통해 데이터에 직접 접근 후, 데이터를 한줄씩 읽음(키값 기준 정렬된 상태임)
- 보조 인덱스: 기본키가 아닌 필드에 대한 인덱스
- 클러스터링 인덱스: 키값 기준 데이터가 물리적으로 정렬됨(기본 인덱스는 클러스터링 인덱스의 한 종류)
- 비클러스터링 인덱스: 데이터가 물리적으로 정렬되지 않음
- 다단계 인덱스: 인덱스 파일에 대한 인덱스 파일이 존재
인덱스 구현에 사용되는 자료구조
B트리
- 모든 노드에 키와 값이 저장됨
- 삽입, 삭제, 재분배 알고리즘 존재(= 쓰기 연산 복잡)
B+트리
- internal 노드에는 키만 저장되고, 리프 노드에 키와 값이 저장됨
- 범위 조회 시 연결 리스트로 빠르게 조회 가능
- 데이터는 리프 노드에만 저장되고 internal 노드는 키만 갖고 있으면 되므로, 메모리 효율이 좋음 = Cache Hit에 유리
- MySQL에서 사용하는 자료구조

Clustered Index vs. Non-Clustered Index
클러스터드 인덱스

특징
- (논클러스터드에 비해)
- select 속도 good
- insert, delete 속도 bad
=> 새로운 데이터 추가될 때 정렬 순서 맞추기 위해 데이터 밀어냄, 리프페이지가 모두 차 있으면 페이지 분할 수행
클러스터드 인덱스 사용이 적합한 상황
- 읽기 작업이 많고 데이터가 자주 삽입-삭제 되지 않는 경우
- 키값을 기준으로 JOIN 이나 WHERE 문을 많이 이용할 때
- MAX, MIN, COUNT등의 쿼리로 범위 또는 Group By 등의 조회를 하는 경우
- 항상 정렬된 방식으로 데이터를 반환해야하는 경우(테이블은 정렬되어있기 때문에 ORDER BY 절을 활용해 모든 테이블 데이터를 스캔하지 않고 원하는 데이터를 조회할 수 있음)
논클러스터드 인덱스
- (클러스터드에 비해)
- select 속도 bad
- insert, delete 속도 good
- 논클러스터드 인덱스의 리프 페이지는 포인터(실제 데이터x)
- 데이터 저장공간 외 인덱스 페이지만을 위한 추가 저장공간 필요

(EX : 12 검색위해 루트 페이지에서 파일 그룹번호 1에 해당하는 리프 페이지 100번으로 이동, 리프 페이지 100번에서 12는 데이터 페이지 1000번의 데이터페이지오프셋 3으로 되어 있음, 데이터 페이지 1000번으로 이동 후 3번째 row로 이동. 12, asdf5 검색 완료)
논클러스터드 인덱스 사용이 적합한 상황
- 데이터가 자주 삽입-삭제 될 경우
- 테이블의 row를 필터링하기 위해 다수의 쿼리가 요구되고, WHERE 문이나 JOIN 문에서 다른 그룹의 컬럼들이 있을 때
클러스터드 인덱스와 논클러스터드 인덱스를 비교하는 테스트 쿼리 수행
- 테스트 환경 세팅: 더미 데이터 100만 건으로 두 테이블 구성
- clustered_table — PK(id)만 존재, 클러스터드 인덱스만 사용
- non_clustered_table — PK(id) + idx_age(age) + idx_dept_salary(department, salary) 복합 논클러스터드 인덱스 추가
(코드 숨기기)
-- 테스트용 DB 생성
CREATE DATABASE index_test;
USE index_test;
-- 클러스터드 인덱스 테이블 (PK = 클러스터드)
CREATE TABLE clustered_table (
id INT NOT NULL AUTO_INCREMENT,
name VARCHAR(100),
age INT,
department VARCHAR(50),
salary INT,
PRIMARY KEY (id) -- 클러스터드 인덱스
);
-- 논클러스터드 인덱스 테이블
CREATE TABLE non_clustered_table (
id INT NOT NULL AUTO_INCREMENT,
name VARCHAR(100),
age INT,
department VARCHAR(50),
salary INT,
PRIMARY KEY (id),
INDEX idx_age (age), -- 단일 논클러스터드
INDEX idx_dept_salary (department, salary) -- 복합 논클러스터드
);
-- 더미 데이터 100만 건 삽입
DELIMITER $$
CREATE PROCEDURE insert_dummy_data()
BEGIN
DECLARE i INT DEFAULT 0;
WHILE i < 1000000 DO
INSERT INTO clustered_table (name, age, department, salary)
VALUES (
CONCAT('user_', i),
FLOOR(20 + RAND() * 40),
ELT(FLOOR(1 + RAND() * 5), 'HR', 'Dev', 'Sales', 'Finance', 'Marketing'),
FLOOR(30000 + RAND() * 70000)
);
INSERT INTO non_clustered_table (name, age, department, salary)
VALUES (
CONCAT('user_', i),
FLOOR(20 + RAND() * 40),
ELT(FLOOR(1 + RAND() * 5), 'HR', 'Dev', 'Sales', 'Finance', 'Marketing'),
FLOOR(30000 + RAND() * 70000)
);
SET i = i + 1;
END WHILE;
END$$
DELIMITER ;
CALL insert_dummy_data();
읽기 성능 비교
- 가설 1. 범위 조회 속도는 클러스터드 인덱스가 빠를 것이다.
- 가설 2. 다중 컬럼 where는 논클러스터드 인덱스가 빠를 것이다.
- 가설 3. GROUP BY가 클러스터드 인덱스 키 기준으로 이루어지면 클러스터드 인덱스가 빠를 것이다.
- 가설 4. GROUP BY가 클러스터드 인덱스 키 기준으로 이뤄지지 않고, 논클러스터드 인덱스의 컬럼들 기준으로 이뤄지면 논클러스터드 인덱스가 빠를 것이다.
(코드 숨기기)
-- 실행 계획 확인 (type, key, rows 컬럼 주목)
EXPLAIN SELECT * FROM clustered_table WHERE id BETWEEN 10000 AND 20000;
EXPLAIN SELECT * FROM non_clustered_table WHERE id BETWEEN 10000 AND 20000;
-- 범위 조회 속도 측정 (클러스터드에 유리할 것이라 예상)
SET @start = NOW(6);
SELECT * FROM clustered_table WHERE id BETWEEN 10000 AND 20000;
SELECT TIMESTAMPDIFF(MICROSECOND, @start, NOW(6)) AS clustered_us;
SET @start = NOW(6);
SELECT * FROM non_clustered_table WHERE id BETWEEN 10000 AND 20000;
SELECT TIMESTAMPDIFF(MICROSECOND, @start, NOW(6)) AS non_clustered_us;
-- 다중 컬럼 WHERE (논클러스터드에 유리할 것이라 예상)
SET @start = NOW(6);
SELECT department, salary FROM non_clustered_table WHERE department = 'Dev' AND salary > 95000;
SELECT TIMESTAMPDIFF(MICROSECOND, @start, NOW(6)) AS non_clustered_multi_us;
SET @start = NOW(6);
SELECT department, salary FROM clustered_table WHERE department = 'Dev' AND salary > 95000;
SELECT TIMESTAMPDIFF(MICROSECOND, @start, NOW(6)) AS clustered_multi_us;
-- GROUP BY
EXPLAIN SELECT department, COUNT(*) FROM clustered_table GROUP BY department;
EXPLAIN SELECT department, COUNT(*) FROM non_clustered_table GROUP BY department;
(클러스터드에 유리할 것이라 예상)
-- id(키값)를 구간으로 나눠 집계
SET @start = NOW(6);
SELECT FLOOR(id / 100000) AS id_range, AVG(salary) FROM clustered_table GROUP BY FLOOR(id / 100000);
SELECT TIMESTAMPDIFF(MICROSECOND, @start, NOW(6)) AS clustered_group_us;
SET @start = NOW(6);
SELECT FLOOR(id / 100000) AS id_range, AVG(salary) FROM non_clustered_table GROUP BY FLOOR(id / 100000);
SELECT TIMESTAMPDIFF(MICROSECOND, @start, NOW(6)) AS non_clustered_group_us;
(논클러스터드에 유리할 것이라 예상)
-- 부서, 급여 기준으로 집계
SET @start = NOW(6);
SELECT department, AVG(salary) FROM clustered_table GROUP BY department;
SELECT TIMESTAMPDIFF(MICROSECOND, @start, NOW(6)) AS clustered_group_us;
SET @start = NOW(6);
SELECT department, AVG(salary) FROM non_clustered_table GROUP BY department;
SELECT TIMESTAMPDIFF(MICROSECOND, @start, NOW(6)) AS non_clustered_group_us;
결과 분석
1. 범위 조회 (id BETWEEN 10000 AND 20000)
가설: 범위 조회 속도는 클러스터드 인덱스가 빠를 것이다.
실행 시간 비교 표
| clustered_table | 7,595ms |
| non_clustered_table | 7,867ms |
- 두 테이블 모두 type: range, key: PRIMARY로 동일한 실행 계획을 사용
- 실행 시간도 약 7.6ms vs 7.9ms로 사실상 차이가 없었음
- InnoDB는 모든 테이블의 PK가 클러스터드 인덱스로 동작하는 특징 때문
참고: MySQL InnoDB 엔진에선 완전한 의미의 non-clustered index가 존재하지 않음
이유
- InnoDB는 모든 테이블이 반드시 클러스터드 인덱스를 가져야 하는 구조라, PK가 없으면 InnoDB가 내부적으로 숨겨진 rowid를 만들어 클러스터드 인덱스로 사용함
- 그래서 데이터 자체가 항상 클러스터드 인덱스의 리프 노드에 존재하게 됨
- 세컨더리 인덱스가 논클러스터드 인덱스 역할에 가깝지만, 실제 row를 찾을 땐 이중 탐색 구조임(1. secondary index 탐색 -> 2. PK 얻음 -> 3. PK로 clustered index 재탐색)
- PostgreSQL이나 SQL Server처럼 힙(heap) 기반 스토리지 엔진은 데이터가 별도 힙에 있고 인덱스가 힙 주소를 가리키는 방식이라 진정한 의미의 논클러스터드 인덱스가 가능함
2. 다중 컬럼 WHERE (department + salary)
가설: 다중 컬럼 where 조회는 논클러스터드 인덱스가 빠를 것이다.
실행 시간 비교 표
| non_clustered (커버링 인덱스) | 13.1ms |
| clustered (풀스캔) | 19.7ms |
=> non_clustered 인덱스가 커버링 인덱스 때문에 성능이 더 우수함
*커버링 인덱스 = 실제 데이터에 접근하지 않고 인덱스에 존재하는 컬럼 값만으로 쿼리를 완성하는 것
3. GROUP BY(클러스터드 인덱스 키 기준)
가설: GROUP BY가 클러스터드 인덱스 키 기준으로 이루어지면 클러스터드 인덱스가 빠를 것이다.
| 인덱스 활용 | 실행 시간 | 비고 | |
| clustered_table | 키 기준 순차 조회 | 13.8ms | 클러스터드 키 활용 |
| non_clustered_table | Using index (커버링) | 15.0ms | 커버링 인덱스 활용 |
- 클러스터드 인덱스 키(id) 기준으로 물리적으로 정렬돼 저장된 클러스터드 인덱스 페이지를 처음부터 끝까지 순차적으로 읽으면 되므로 랜덤 I/O가 발생하지 않아 클러스터드 인덱스가 더 빠름
4. GROUP BY(다중 컬럼 기준)
가설: GROUP BY가 클러스터드 인덱스 키 기준으로 이뤄지지 않고, 논클러스터드 인덱스의 컬럼들 기준으로 이뤄지면 논클러스터드 인덱스가 빠를 것이다.
| 인덱스 활용 | 실행 시간 | 비고 | |
| clustered_table | Using temporary(풀스캔) | 10078241 | ALL (인덱스 미존재) |
| non_clustered_table | Using index (커버링) | 9245936 | idx_dept_salary (복합 인덱스 활용) |
- clustered_table은 department에 인덱스가 없어 풀스캔 후 임시 테이블을 만들어 집계
- non_clustered_table은 idx_dept_salary (department, salary) 복합 인덱스로 커버링 인덱스 처리 → 테이블 자체를 아예 안 읽음
UPDATE 성능 비교
*정확한 Update 성능 비교를 위해 버퍼풀 초기화 필요
이유
- InnoDB의 Update는 버퍼풀(메모리)에서 먼저 일어나고, 이후 디스크에 반영되기 때문
- 버퍼풀을 초기화하지 않으면 이미 캐시된 데이터 페이지가 존재해 정확한 결과값을 얻을 수 없음
- dirty page를 디스크에 반영하는 작업이 Update 작업과 겹치면 정확한 결과값을 얻을 수 없음
(코드 생략)
-- ① 버퍼풀 초기화
SET GLOBAL innodb_buffer_pool_size = @@innodb_buffer_pool_size;
SELECT SLEEP(3);
-- ② clustered UPDATE 전 상태 스냅샷
SELECT variable_value INTO @before_requests
FROM performance_schema.global_status WHERE variable_name = 'Innodb_buffer_pool_read_requests';
SELECT variable_value INTO @before_reads
FROM performance_schema.global_status WHERE variable_name = 'Innodb_buffer_pool_reads';
-- ③ clustered UPDATE 측정
SET @start = NOW(6);
UPDATE clustered_table SET salary = salary + 1000 WHERE age BETWEEN 25 AND 35;
SELECT TIMESTAMPDIFF(MICROSECOND, @start, NOW(6)) AS clustered_update_us;
-- ④ clustered UPDATE 후 캐시 히트율 확인
SELECT variable_value INTO @after_requests
FROM performance_schema.global_status WHERE variable_name = 'Innodb_buffer_pool_read_requests';
SELECT variable_value INTO @after_reads
FROM performance_schema.global_status WHERE variable_name = 'Innodb_buffer_pool_reads';
SELECT
(@after_requests - @before_requests) AS total_requests,
(@after_reads - @before_reads) AS disk_reads, -- 이 값이 작을수록 캐시 히트
ROUND(100 - (@after_reads - @before_reads) / (@after_requests - @before_requests) * 100, 2) AS hit_rate_pct;
-- ⑤ 버퍼풀 다시 초기화
SET GLOBAL innodb_buffer_pool_size = @@innodb_buffer_pool_size;
SELECT SLEEP(3);
-- ⑥ non_clustered UPDATE 동일하게 반복
SELECT variable_value INTO @before_requests
FROM performance_schema.global_status WHERE variable_name = 'Innodb_buffer_pool_read_requests';
SELECT variable_value INTO @before_reads
FROM performance_schema.global_status WHERE variable_name = 'Innodb_buffer_pool_reads';
SET @start = NOW(6);
UPDATE non_clustered_table SET salary = salary + 1000 WHERE age BETWEEN 25 AND 35;
SELECT TIMESTAMPDIFF(MICROSECOND, @start, NOW(6)) AS non_clustered_update_us;
SELECT variable_value INTO @after_requests
FROM performance_schema.global_status WHERE variable_name = 'Innodb_buffer_pool_read_requests';
SELECT variable_value INTO @after_reads
FROM performance_schema.global_status WHERE variable_name = 'Innodb_buffer_pool_reads';
SELECT
(@after_requests - @before_requests) AS total_requests,
(@after_reads - @before_reads) AS disk_reads,
ROUND(100 - (@after_reads - @before_reads) / (@after_requests - @before_requests) * 100, 2) AS hit_rate_pct;
결과 분석
| clustered | non_clustered | |
| 변경 행 수 | 274,862 | 274,968 |
| 실행 시간 | 12.2ms | 35.5ms |
| total_requests | 1,556,165 | 4,885,239 |
| disk_reads | 0 | 1,883 |
| hit_rate | 100% | 99.96% |
clustered UPDATE 흐름
풀스캔으로 age 조건 행 탐색
→ 해당 페이지에서 salary 바로 수정 (끝)
→ 갱신할 세컨더리 인덱스 없음
non_clustered UPDATE 흐름
풀스캔으로 age 조건 행 탐색
→ salary 수정
→ idx_dept_salary (department, salary) 인덱스 엔트리 삭제 후 재삽입 (274,968회)
→ idx_age (age) 인덱스도 확인 및 갱신 (274,968회)- 둘 다 풀스캔으로 age조건을 탐색하는 건 동일
- 논클러스터드 인덱스는 급여 항목을 바꿀 때 부서-급여 인덱스도 변경해야 하고 나이 인덱스도 확인해야 함
- 결국 클러스터드 인덱스가 3배 빠름
8장: 관계형 대수
피연산자는 릴레이션(테이블), 연산자는 관계형 대수
'1+2=3'에서 피연산자는 1,2이고 연산자는 +
집합 연산자: 합집합(union), 교집합(intersect), 차집합(difference), 곱집합(카티션 프로덕트)
곱집합을 제외한 연산은 두 릴레이션의 차수(col 개수)가 같아야 함
순수 관계형 연산자: 셀렉트(row 추출), 프로젝트(col 추출. pi), 조인, 디비전(/), 외부 합집합(outer union)
조인 종류: natural join, outer join(left, right, full), semi join(natural join 후 한쪽 릴레이션의 결과만 반환)
10장: SQL(Structured Query Language)
SQL은 관계형 대수와 관계형 해석을 기반으로 개발된 데이터 언어
책에서 문법 위주의 설명
데이터 정의어: create, alter, drop, truncate(롤백 불가능)
데이터 조작어: select, insert, update, delete
- 집계함수(count, sum 등)는 where절에 사용 불가
- 서브쿼리의 결과가 하나이면 =, <, > 같은 연산자를, 다수의 투플이면 in, exists 같은 연산자를 사용
삽입 SQL
- C, Java 등 프로그램 속에 SQL이 삽입된 형태
- C 프로그램의 호스트 변수를 SQL이 가져와 사용 가능
- SQL 결과가 여러 투플인 경우, cursor를 사용해 loop로 레코드 하나씩 반복 접근
*JDBC = 자바 프로그램과 DB를 연결하는 프로그래밍 방식. Java 애플리케이션은 JDBC 드라이버를 설치해 DB와 통신
SQL 뷰
- 가상 테이블
- 원본 테이블에서 필요한 부분만 가져와 사용. 매번 질의할 필요 없음
- create view 구문 사용
- with절을 이용한 CTE(Common Table Expression)은 일회성 임시 결과지만, 뷰는 영구 저장됨
- 데이터 접근 제한(정보 보호) 용도로 사용 가능
동적 SQL
- 쿼리를 저장해두고 매번 컴파일해 SQL 실행에 사용
- 쿼리를 미리 지정하고 파라미터를 사용한다는 점에서 Prepared Statement와 유사
- Prepared Statement는 컴파일된 쿼리를 캐시에 저장한 뒤 파라미터만 바인딩하여 재사용하므로 동적 SQL보다 효율적
12장: 데이터베이스 설계
데이터베이스 개발의 라이프 사이클
폭포수 모델 기준: 요구사항 분석 <-> 설계 <-> 구현 <-> 운영 <-> 감시 및 개선
요구사항 분석 및 설계 단계: 요구사항 분석 <-> 개념적 설계 <-> 논리적 설계 <-> 물리적 설계
요구사항 분석: 요구사항 명세서 작성
- 요구사항 명세서에 회사 전반에 대한 정보 등 업무 요구사항, DFD(data flow diagram. 데이터 흐름도), 트랜잭션 유형 및 실행 빈도 등 반영
- DFD 예시: {데이터 저장소} --{데이터 흐름}--> {처리 과정} --{데이터 흐름}--> {데이터 저장소} --... 같은 흐름의 집합을 하나의 종이에 그림
개념적 설계
- 개념적 스키마 모델링: E-R 다이어그램을 사용한 모델링. 개체, 속성, 관계 등을 추상화해 표현
논리적 설계
- E-R 다이어그램을 테이블로 만들기
물리적 설계
- 데이터가 실제 저장되는 물리적 구조 설계
- 저장 레코드 양식: 투플을 바이트 단위로 구체화한 것. 데이터 타입 및 길이는 어떻게 할건지, 고정 길이와 가변 길이 중 어떤 걸로 할건지, 자주 사용되는 데이터는 물리적으로 위치 최적화
- 레코드 집중화: 논리적 연관성 높은 레코드들을 물리적으로도 근접 저장해 효율적 검색 유도, 적당한 블록 사이즈 선택(크면 순차 처리에 유리, 작으면 임의 접근 처리에 유리)
- 접근 경로: 인덱스를 어떻게 구성할 건지
14장: 병행 제어
트랜잭션 = 하나의 논리적 기능을 수행하기 위한 작업의 단위
트랜잭션 실행 전/후가 달라져 일관성이 없어지는 모순 상태가 발생해선 안됨
트랜잭션 특징: ACID
- 원자성(Atomicity): All or Nothing(트랜잭션이 DB에 모두 반영되거나 아예 반영되지 않거나)
- 일관성(Consistency): 트랜잭션 실행 전에도, 실행 후에도 일관된 상태
- 격리성(Isolation): 한 트랜잭션이 실행되는 도중 다른 트랜잭션이 영향을 주면 안됨
- 영속성(Durability): 트랜잭션이 완료돼 DB에 반영한 내용은 영구히 저장
병행 제어 문제 상황: 여러 트랜잭션이 동시에 실행될 때 트랜잭션 간 간섭으로 예기치 못한 결과 생성
발생 가능한 문제 예시: 갱신 분실, 모순성, 연쇄 복귀
갱신 분실 모순성


연쇄 복귀

- 트랜잭션b가 commit을 완료한 뒤 트랜잭션a가 rollback을 시도하면 트랜잭션b도 rollback해야 일관성이 유지되지만
- 트랜잭션b는 이미 commit 완료 상태이므로 rollback 불가능
- => 트랜잭션a만 rollback 수행해 일관성 문제 발생
- 병행 제어 기법의 목적: 트랜잭션 스케줄의 직렬 가능성 보장
- 트랜잭션 스케줄: 트랜잭션 연산들의 실행 순서 지정
- 직렬 스케줄: 트랜잭션 T1이 실행을 모두 마친 후에만 트랜잭션 T2가 실행 -> 일관성 보장
- 비직렬 스케줄: 트랜잭션이 병행 수행하는 스케줄. 인터리빙(끼워넣기) 허용
- 직렬 가능 스케줄: 비직렬 스케줄이지만, 정확한 결과를 만드는 스케줄
공유 잠금(Shared Lock) = Read Lock
- 트랜잭션이 읽기를 할 때 사용하는 락
- 데이터를 읽기만하기 때문에 같은 공유락 끼리는 동시 접근 가능
- 공유락이 설정된 데이터에는 배타락을 사용할 수 없음
- 주로 'S'로 표기
배타적 잠금(Exclusive Lock) = Write Lock = 전용 락
- 데이터를 변경할 때 사용하는 락
- 트랜잭션이 완료될 때까지 유지되며, 배타락이 끝나기 전까지 어떠한 접근도 허용하지 않음
- 배타락은 락이 해제될 때까지 다른 트랜잭션(읽기 포함)이 해당 리소스에 접근할 수 없음
- 주로 'X'로 표기
- 2단계 로킹 규약을 따르면 스케줄의 직렬 가능성이 보장됨
- 확장 단계: 트랜잭션은 새로운 lock연산만 실행할 수 있고 unlock 연산은 수행할 수 없는 단계
- 축소 단계: 트랜잭션은 unlock 연산만 실행할 수 있고 unlock 연산을 수행하면 lock 연산은 더 이상 실행할 수 없는 단계

교착 상태(deadlock)
두 트랜잭션이 각각 Lock을 설정하고 서로의 Lock에 접근하여 값을 얻어오려고 할 때 발생되는 무한대기상태
데드락 조건 4가지
- 상호 배제: 한 트랜잭션이 점유한 자원은 다른 트랜잭션이 사용하지 못함
- 대기: 한 자원을 점유 중인 트랜잭션이 다른 자원을 요구함
- 비선점: 다른 트랜잭션이 점유 중인 자원을 강제로 뺏을 수 없음
- 순환 대기: 자원 대기 그래프에 사이클이 발생
데드락 회피 방법
- wait-die 기법: T1이 T2의 자원을 요구할 때, T1이 고참이면 기다리고(wait) 신참이면 포기하기(die)
- wound-wait 기법: T1이 T2의 자원을 요구할 때, T1이 고참이면 선점(wound)하고 신참이면 기다리기(wait)

데드락 예방 방법: 트랜잭션 실행 전에 필요한 lock을 한번에 부여받기
=> 어떤 데이터의 lock을 필요로 할지 사전에 알기 어렵기 때문에 실효성 낮음
데드락 탐지 방법: 대기 그래프를 작성해 사이클이 생기면 데드락임을 판단. 작업이 가장 적게 수행된 트랜잭션을 취소시켜 사이클 제거
그 외: 사용자 가이드 제공(트랜잭션 단위를 쪼개기, 재처리 로직 수행 등), 애플리케이션 단의 로직 수정
2단계 로킹 규약 예시
- 다중 버전 동시성 제어(MVCC): 데이터를 변경할 때 이전 데이터를 '언두 로그'에 남겨두어, 다른 트랜잭션이 이전 버전의 데이터를 읽을 수 있음
- 트랜잭션 격리수준: 여러 트랜잭션이 동시에 처리될 때, 트랜잭션끼리 얼마나 서로 고립되어 있는지를 나타내는 것
1) READ UNCOMMITTED: 다른 트랜잭션에서 커밋되지 않은 내용도 참조할 수 있음
- 트랜잭션 A에서 데이터를 변경하는 중에 B에서 해당 데이터를 접근하고, A가 다시 롤백하면 B는 중간에 수정한 데이터로 읽음
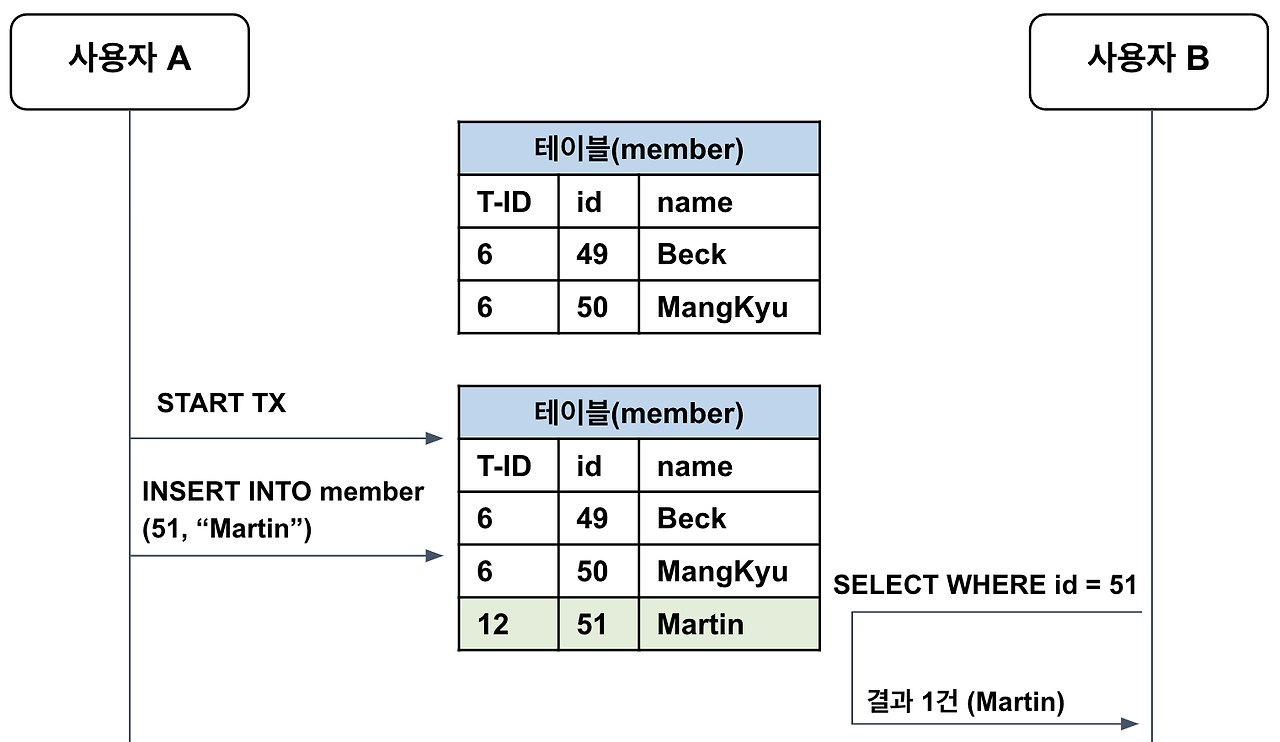

- Dirty Read: 어떤 트랜잭션의 작업이 완료되지 않았는데도, 다른 트랜잭션에서 볼 수 있는 부정합 문제
2) READ COMMITTED: 다른 트랜잭션에서 커밋된 내용만 참조할 수 있음
- NON-REPEATABLE READ 부정합 문제가 발생 가능. 하나의 트랜잭션 내에서 똑같은 select 를 수행했을 경우 항상 같은 결과를 반환해야 한다는 repeatable read 정합성에 어긋남

3) REPEATABLE READ: 트랜잭션에 진입하기 이전에 커밋된 내용만 참조할 수 있음
3-1. MVCC(변경 전의 데이터는 언두 로그에 저장하기 때문에 한 레코드에 여러 버전의 데이터 존재)를 이용해 한 트랜잭션 내에서 동일한 결과를 보장하지만, 새로운 레코드가 추가되는 경우에 부정합 발생

3-2. Phantom Read: 다른 트랜젹션에서 수행한 작업에 의해 레코드가 안보였다 보였다 하는 현상

3-3. MySQL은 갭 락이 존재해 Phantom Read가 거의 발생하지 않음
*갭 락: 인덱스 레코드 사이의 빈 공간(Gap)에 락을 걸어서, 다른 트랜잭션이 그 사이에 새로운 데이터를 INSERT 하지 못하게 막는 락

3-4. 유일하게 아래 경우에만 MySQL도 Phantom Read 발생(사용자 B가 처음 SELECT 때 아무 잠금 없이 조회한 경우)


4) SERIALIZABLE: 트랜잭션이 시작하면 락을 걸어 다른 트랜잭션이 접근하지 못하게 함(성능 매우 떨어짐)
격리 수준 정리
| 격리 수준 | Dirty Read | Non-Repeatable Read | Phantom Read |
| READ UNCOMMITTED | O | O | O |
| READ COMMITTED | X | O | O |
| REPEATABLE READ | X | X | O |
| SERIALIZABLE | X | X | X |
사용처
- Read Uncommitted: 정합성보다 속도가 중요한 단순 통계 수집
- Read Committed 또는 Repeatable Read(MySQL 기본값): 일반적인 웹 서비스
- Serializable 또는 매우 엄격한 락: 돈이 오가는 금융권, 핀테크
궁금증
- 실무에서의 MySQL DB는 기본값인 Repeatable Read를 그대로 사용하는지, 아니면 상황에 따라 격리 수준을 낮추거나(예: Read Committed) 높여서 사용하는 경우가 있는지
=> 상황에 따라 세션 단위로 고립수준 레벨을 낮춰서 사용하는 경우가 있음
'인턴' 카테고리의 다른 글
| [장애 이력 자동 작성 도구5] 두레이 태스크로 등록 (0) | 2026.03.05 |
|---|---|
| [장애 이력 자동 작성 도구4] 로그 수집 스크립트 작성(OOM Killed 상황) (0) | 2026.03.05 |
| [스터디3] MySQL 스터디 발표 질문대비 (0) | 2026.03.04 |
| [스터디3] MySQL 스터디 발표자료 - deprecated (0) | 2026.02.28 |
| [장애 이력 자동 작성 도구3] Redis OOM 장애 상황 연출 (0) | 2026.02.27 |


