
ssuperjun 님의 블로그
[장애 이력 자동 작성 도구11] Redis 복제 구조 장애 상황 연출 및 로그 수집 코드 구현 본문
목표
cb801에 있는 기존의 redis-server를 마스터로 하고(불가능하다면 재설치), ca801 서버(cb801과는 다른 서버)에 슬레이브를 설치
1. cb801의 bind 설정 변경
=> 현재 cb801의 redis-server가 127.0.0.1:6379로 바인딩되어 있는데, ca801에서 접속하려면 cb801의 bind 설정을 0.0.0.0 또는 10.150.254.155로 변경해야 함
# cb801에서 - redis.conf bind 설정 확인
sudo grep "^bind" /etc/redis/redis.conf
2. ca801에서 cb801과 통신 - IP로 직접 연결 확인
# ca801에서
telnet cb801주소 6379=> 네트워크 연결 확인됨
3. protected mode와 인증 문제 => 복제 구성이므로 비밀번호 설정 방식으로 해결
cb801 redis.conf에 requirepass와 masterauth를 설정하고, protected mode는 비밀번호 설정 시 자동으로 해제
# 현재 requirepass, protected-mode 설정 확인
sudo grep -E "^requirepass|^protected-mode|^masterauth" /etc/redis/redis.conf출력값: protected-mode yes
비밀번호 설정하고 protected mode 해제하기
# redis.conf에 requirepass 추가 및 protected-mode 비활성화
sudo sed -i 's/^protected-mode yes/protected-mode no/' /etc/redis/redis.conf
echo "requirepass testpass1234" | sudo tee -a /etc/redis/redis.conf
echo "masterauth testpass1234" | sudo tee -a /etc/redis/redis.conf
# 설정 확인
sudo grep -E "^requirepass|^protected-mode|^masterauth" /etc/redis/redis.conf
# redis-server 재시작
sudo systemctl restart redis-server
sudo systemctl status redis-server
# 비밀번호 인증 확인
redis-cli -p 6379 -a testpass1234 ping
4. ca801에서 apt로 redis 설치
# ca801에서
sudo apt update && sudo apt install -y redis-server
redis-server --version
5. ca801을 cb801의 슬레이브로 연결하기 - ca801의 redis.conf를 수정
# ca801에서 - redis.conf 위치 확인
sudo grep -E "^bind|^requirepass|^masterauth|^replicaof|^slaveof" /etc/redis/redis.conf
# ca801에서
sudo sed -i 's/^bind 127.0.0.1 -::1/bind 127.0.0.1 10.150.254.183/' /etc/redis/redis.conf
echo "replicaof 10.150.254.155 6379" | sudo tee -a /etc/redis/redis.conf
# 설정 확인
sudo grep -E "^bind|^replicaof" /etc/redis/redis.conf
# 재시작
sudo systemctl restart redis-server
sudo systemctl status redis-server
6. 복제 연결 상태 확인
# cb801에서 - 슬레이브 연결 확인
redis-cli -p 6379 -a testpass1234 info replication
# ca801에서 - 마스터 연결 상태 확인
redis-cli -p 6379 -a testpass1234 info replication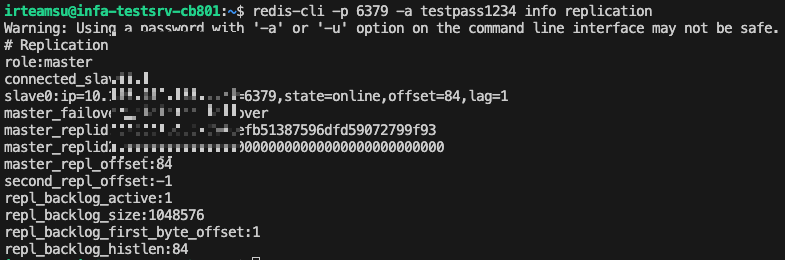
7. 각 장애 시나리오를 순서대로 연출하기 전에, 로그 위치 확인
# cb801에서 - redis 로그 위치 확인
sudo grep "^logfile" /etc/redis/redis.conf
# ca801에서 - redis 로그 위치 확인
sudo grep "^logfile" /etc/redis/redis.conf출력 결과: logfile /var/log/redis/redis-server.log
시나리오 1: 마스터 OOM Kill
# cb801에서 - 순서대로 진행
# 1. MemoryLimit 해제
sudo systemctl set-property redis-server.service MemoryLimit=infinity
# 2. RDB 저장을 비활성화하기
# 실행 중인 redis에서 현재 적용된 rdb 설정 확인
redis-cli -p 6379 -a testpass1234 config get save
# RDB 비활성화 (redis.conf에서 save 설정 주석 처리)
sudo sed -i 's/^save /#save /g' /etc/redis/redis.conf
echo 'save ""' | sudo tee -a /etc/redis/redis.conf
# 기존 rdb 파일 삭제
# cb801에서
# 기존 RDB 파일 삭제
sudo rm /var/lib/redis/dump.rdb
# 현재 메모리의 키 데이터 삭제
redis-cli -p 6379 -a testpass1234 flushall
# 메모리 사용량 확인
redis-cli -p 6379 -a testpass1234 info memory | grep used_memory_human
# 3. 로그 초기화
sudo truncate -s 0 /var/log/redis/redis-server.log
# 4. 재시작
sudo systemctl daemon-reload
sudo systemctl reset-failed redis-server
sudo systemctl start redis-server
# 5. 확인
sudo systemctl status redis-server
redis-cli -p 6379 -a testpass1234 ping
redis-cli -p 6379 -a testpass1234 config get save
OOM 장애 상황 연출
# cb801, ca801 양쪽 로그 초기화
sudo truncate -s 0 /var/log/redis/redis-server.log
# cb801에서 - MemoryLimit 낮춰서 OOM Kill 유발
sudo systemctl set-property redis-server.service MemoryLimit=100M
sudo systemctl daemon-reload
# cb801 redis에 메모리 채우기
# cb801에서
# swap 비활성화 확인
free -h
# swap이 있으면 비활성화
sudo swapoff -a
# 가상환경 생성 및 redis 패키지 설치
python3 -m venv venv-redis
venv-redis/bin/pip install redis
# cb801에서 메모리 채우기 실행
sudo venv-redis/bin/python3 -c "
import redis, os
r = redis.Redis(password='testpass1234')
print('메모리 채우기 시작')
for i in range(1000000):
r.set(f'key:{i}', os.urandom(1024))
if i % 10000 == 0:
print(f'{i}개 삽입')
"
로그 확인
# cb801 로그
sudo cat /var/log/redis/redis-server.log
# ca801 로그
sudo cat /var/log/redis/redis-server.log

로그 수집 코드 구현 시작
발생 시각 기준: 가장 최근 장애 묶음의 첫 번째 kill 이벤트 시각
- 장애 묶음 경계: 연속된 kill/conn_lost 이벤트 중 직전 이벤트와의 gap이 30초 이상이면 새 묶음으로 판단
- gap이 30초인 이유는 싱글 구성과 동일(OOM Kill 후 재시작까지 수초, BGSAVE(슬레이브 동기화를 위한 rdb 구성 위해 필요) fork 후 동기화까지 수초 수준이므로)
| 원인 | 감지 키워드 | 태그 |
| OOM Kill | Failed with result 'oom-kill' (마스터 journalctl) | [OOM_KILL] |
| Segfault | Failed with result 'core-dump' (마스터 journalctl) | [SEGFAULT] |
| Signal Kill | Failed with result 'signal' (마스터 journalctl) | [KILL_SIGNAL] |
슬레이브 측 연동 태그
| 태그 | 감지 키워드 |
| [CONN_LOST] | Connection with master lost |
| [FULL_RESYNC] | Full resync from master |
| [SYNC_FAIL] | I/O error trying to sync with MASTER |
| [SYNC_OK] | MASTER <-> REPLICA sync: Finished with success |
| [PSYNC_OK] | Successful partial resynchronization |
마스터 측 연동 태그
| 태그 | 감지 키워드 |
| [REPLICA_CONN] | Synchronization with replica .* succeeded |
정상화 판단: 마지막 [REPLICA_CONN] 또는 [SYNC_OK]/[PSYNC_OK] 이후 30초 동안 [CONN_LOST] 없음
코드 구현 내용 요약
스크립트 추가 내용
- REPL_LOG_PATH, REPL_SLAVE_HOST 상수 (conf [replication] 섹션 읽음)
- collect_replication_events() — 마스터 journalctl + 마스터/슬레이브 redis 로그 수집
- extract_replication_incident() — 마지막 장애 묶음 추출 (싱글과 동일한 gap 방식)
- detect_replication_recovery() — 마지막 REPLICA_CONN/SYNC_OK 후 30초 안정화 판단
- build_replication_timeline() — 통합 타임라인 구성 (PSYNC_TRY, CONN_REFUSED, REPLICA_REQ는 노이즈로 생략)
- run_replication_mode() — 메인 플로우 + 두레이 연동
- main --slave [user@slavehost] 옵션 파싱 및 분기
실행 명령어
# 슬레이브 명시
python3 collect_redis_incident.py irteamsu@infa-testsrv-cb801 --slave irteamsu@infa-testsrv-ca801 --tunnel
# 슬레이브 생략 (conf의 slave_host 사용)
python3 collect_redis_incident.py irteamsu@infa-testsrv-cb801 --slave --tunnel
실행 결과 사진
타임라인 작성 시 마스터와 슬레이브 양쪽 로그를 시간 순으로 나열하되, 태그와 원본 로그 사이에 마스터/슬레이브를 구분하는 글자(ex. (master)) 사용

여기까지 복제 구성에서의 시나리오 1(마스터 OOM Kill)에 대한 코드 구현을 완료함
추가 가능한 시나리오
- 슬레이브 OOM Kill / Segfault — 슬레이브 프로세스가 죽는 경우. 마스터 로그에는 Connection with replica lost, Replica X asks for synchronization이 찍히고, 슬레이브 journalctl에서 kill 이벤트가 발생
- 복제 지연 (Replication Lag) — 슬레이브가 살아있지만 마스터를 따라가지 못하는 경우. redis 로그에는 직접 찍히지 않고 INFO replication의 master_repl_offset vs slave_repl_offset 차이로만 확인 가능. 로그 기반 수집이 불가능하므로 현재 스크립트 방식으로는 구현 불가.
- 복제 연결 단절 (master_link_status:down) — 네트워크 단절 등으로 슬레이브가 마스터에 접근 불가한 경우. 슬레이브 로그에 Connection with master lost + Error condition on socket for SYNC: Connection refused가 반복되는 패턴인데, 이미 현재 구현에서 [CONN_LOST], [CONN_REFUSED]로 수집하고 있음. 단, 지금은 마스터 kill과 함께 발생하는 케이스만 테스트했고, 순수 네트워크 단절(마스터는 살아있지만 연결 불가) 케이스는 별도 시나리오로 연출이 필요합니다.
1안: 필요 없음. 싱글 구성을 가정해 슬레이브에 스크립트를 실행하면 됨
2안: 로그 기반 수집 불가능 - redis 내부에서 db단의 명령어(redis-cli INFO replication 명령)를 실행해 나온 출력값을 기반으로 복제 지연을 확인 가능(master_repl_offset vs slave_repl_offset 차이) => 스크립트 실행 시점에는 이런 정보가 이미 휘발되므로 현재 스크립트 방식과는 맞지 않음
3안: 순수 네트워크 단절(마스터는 살아있지만 연결 불가) 케이스만 연출 필요 - 현재로선 kill이 없으면 [CONN_LOST]만 반복되는 케이스에 대한 장애 감지가 불가능한 상황
네트워크 차단 장애 연출
# cb801에서 메모리 제한 임시 해제
=> OOM kill을 위해 설정한 100MB 메모리 제한을 그대로 놔두면, 복구 시 슬레이브가 Full resync를 시도하는 과정에서 마스터가 BGSAVE fork 도중 OOM Kill될 수 있음
sudo redis-cli -h 127.0.0.1 -p 6379 -a testpass1234 CONFIG SET maxmemory 0
1. 장애 연출 (cb801에서 실행)
# ca801(10.150.254.183) 방향 패킷 차단
# cb801에서 실행
sudo iptables -D OUTPUT -d 10.150.254.183 -p tcp --dport 6379 -j DROP
sudo iptables -A OUTPUT -d 10.150.254.183 -p tcp --dport 6379 -j REJECT
실패해, cb801의 Redis에서 직접 슬레이브 연결을 끊는 방법 사용
# cb801에서 기존 룰 제거
sudo iptables -D OUTPUT -d 10.150.254.183 -p tcp --dport 6379 -j REJECT
# ca801에서 오는 연결을 INPUT에서 차단
sudo iptables -A INPUT -s 10.150.254.183 -p tcp --dport 6379 -j REJECT
# 이후 다시 슬레이브 연결 끊기
sudo redis-cli -h 127.0.0.1 -p 6379 -a testpass1234 CLIENT KILL ID 4
# 연결된 슬레이브 클라이언트 ID 확인
sudo redis-cli -h 127.0.0.1 -p 6379 -a testpass1234 CLIENT LIST
# 슬레이브 연결 강제 종료 (id= 값으로)
sudo redis-cli -h 127.0.0.1 -p 6379 -a testpass1234 CLIENT KILL ID <id>
2. 슬레이브 로그 확인 (ca801에서 실행)
sudo tail -f /var/log/redis/redis-server.log=> Connection with master lost → Error condition on socket for SYNC: Connection refused 패턴이 반복되면 장애 연출 성공
3. 복구 (cb801에서 실행)
sudo iptables -D OUTPUT -d 10.150.254.183 -p tcp --dport 6379 -j DROP=> 복구 후 슬레이브 로그에 MASTER <-> REPLICA sync: Finished with success가 찍히면 정상화
3안(복제 연결 단절) 구현 요약
extract_replication_incident 수정
기존에는 kill 이벤트가 없으면 전체를 그대로 반환했는데, 이제 kill_types | conn_lost를 묶어 fault_events로 통합하고 fault 이벤트 간 gap 기준으로 최근 묶음을 추출. kill이 있는 경우에도 CONN_LOST가 함께 포함되므로 기존 OOM Kill 케이스도 그대로 동작함.
run_replication_mode 원인 판단 추가
kill 이벤트가 없고 conn_lost만 있으면 "복제 연결 단절 (원인 수동 확인 필요)"를 반환함. 네트워크 단절, 슬레이브 설정 오류 등 다양한 원인이 있을 수 있어 수동 확인을 유도함.
실행 결과 사진
장애 복구 전 스크립트 실행

장애 복구 후 스크립트 실행(기존에 작성된 두레이 태스크 업데이트)


참고
복제 구성에서 bgsave가 발생하는 이유
- save ""로 디스크 저장용 RDB는 비활성화했지만, 슬레이브 Full resync 시에는 마스터가 현재 데이터를 슬레이브에 전송하기 위해 별도로 BGSAVE를 수행함
- 이 bgsave는 save 설정과 무관하게 동작함
- 이번 로그에서 Starting BGSAVE for SYNC with target: replicas sockets라고 찍힌 것이 바로 이 경우에 해당함
- replicas sockets는 디스크에 파일을 쓰지 않고 RDB 데이터를 소켓으로 직접 슬레이브에 스트리밍하는 diskless replication 방식임
- 이 BGSAVE는 fork()로 자식 프로세스를 생성하는데, fork 순간 부모 프로세스의 메모리를 복사하므로 메모리 사용량이 일시적으로 급증해서 다시 OOM Kill이 발생함
- diskless replication을 비활성화(repl-diskless-sync no)하면 디스크에 RDB 파일을 먼저 쓴 후 전송하는데, 이 경우 fork 시 메모리 부담은 줄어들지만 디스크 I/O가 발생함. 어느 쪽이든 MemoryLimit이 낮으면 OOM Kill 반복은 피하기 어려움
replicaof "IP" "PORT" 명령어
지금은 ca801의 redis를 cb801 redis의 슬레이브로 연결하기 위해 ca801의 redis.conf를 수정했는데, 이 방법 말고 replicaof "IP" "PORT" 명령어를 이용하는 방법도 있음
- redis.conf 수정 방식: 파일을 수정한 뒤 재시작해야만 적용됨. 재시작 후에도 복제 설정이 유지됨
- replicaof 명령어 방식: 런타임에만 적용되고, 재시작하면 복제 설정이 사라짐
- 실무에선 config rewrite 명령을 이용: replicaof 명령어를 사용한 뒤 메모리 상의 변경된 설정을 redis.conf 파일에 물리적으로 덮어쓰도록 config rewrite 사용하면 재시작 없이도 복제 설정이 영구적으로 유지됨
'인턴' 카테고리의 다른 글
| [장애 이력 자동 작성 도구 13] MySQL 최종 정리 (0) | 2026.03.12 |
|---|---|
| [장애 이력 자동 작성 도구12] Redis 스크립트 추가 고도화 (0) | 2026.03.10 |
| [장애 이력 자동 작성 도구10] Redis Sentinel 구조 장애 로그 수집 코드 구현 (0) | 2026.03.10 |
| [장애 이력 자동 작성 도구9] Redis Segfault 장애 상황 연출 및 로그 수집 코드 구현 (0) | 2026.03.10 |
| [장애 이력 자동 작성 도구8] Redis Too many connections(maxclients 초과) 장애 상황 연출 및 deprecated 이유 & CPU 병목 스킵 이유 (0) | 2026.03.10 |



