
ssuperjun 님의 블로그
[장애 이력 작성 도구] 발표 이후 고도화3 - 새 아이디어(장애 발생 당시 DB 상태 정보 수집) 구상, 아키텍처 설계 본문
[고도화 아이디어]
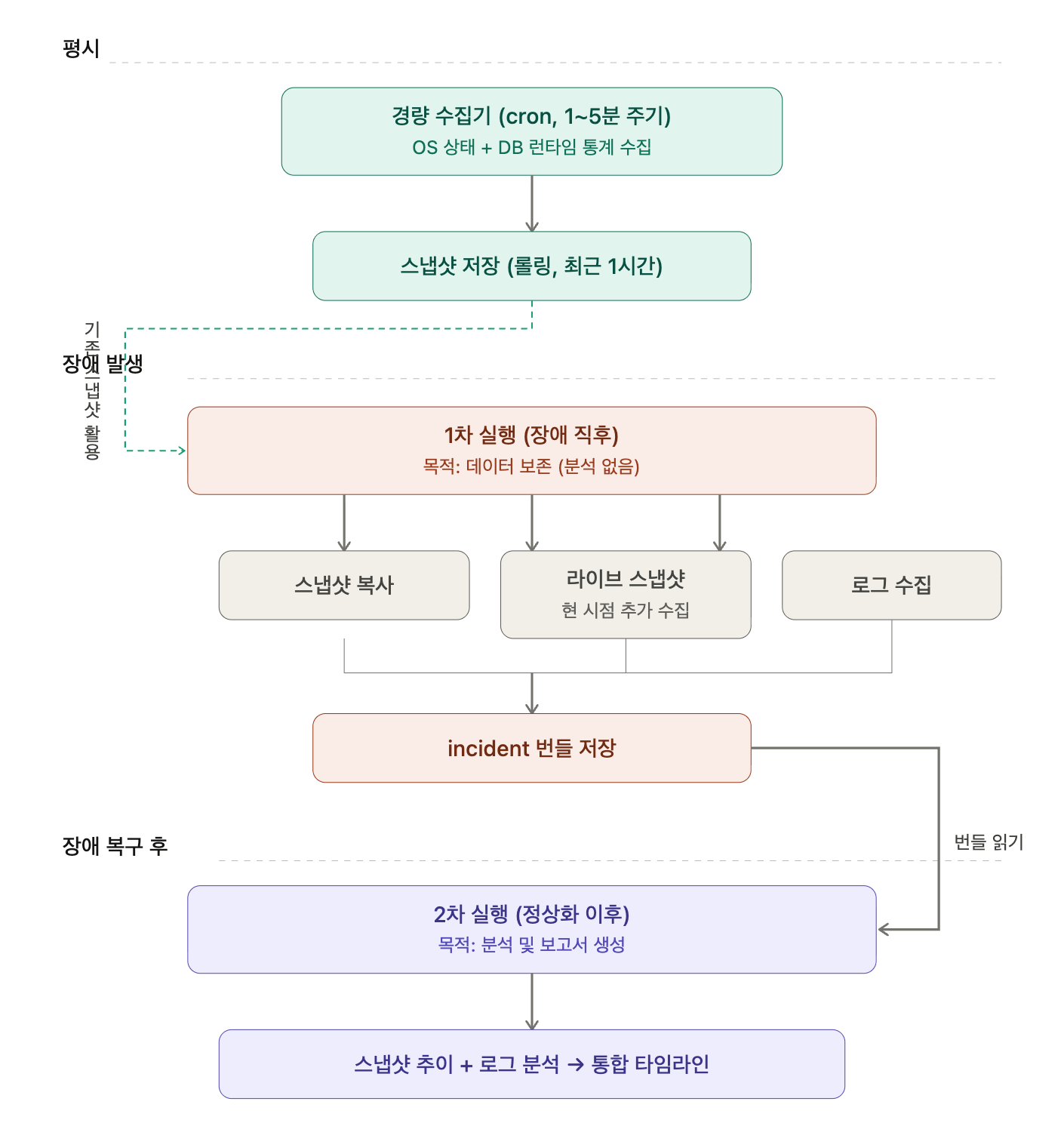
장애 발생 직후 스크립트 1차 실행(원인 분석 및 휘발성 상태 정보 보존 목적) -> 2차 실행(정상화 이후)
[기존 문제점]
기존의 journalctl 및 db 로그 수집 방식은 장애 발생 당시의 db 상태 정보를 수집하지 못함
이로 인해 기존 스크립트는 디스크 full, cpu 병목, too many connections, 복제 지연 등의 상황을 커버하지 못함
[목적]
이 아이디어를 적용하면, 디스크 full, cpu 병목, too many connections, 복제 지연 등의 런타임 통계 정보를 수집해 더 많은 장애 상황에 대한 타임라인을 작성할 수 있음
2차 실행 시, 1차 실행 때 수집했던 db 상태 정보를 활용해 더 고도화된(풍성한 정보의) 타임라인을 산출할 수 있음
실용적인가?
=> 현재 스크립트가 못 잡는 장애 상황을 1차 실행으로 커버할 수 있음
MySQL 기준
- 디스크 full → df -h, du 스냅샷, SHOW VARIABLES LIKE 'datadir' 경로 확인
- CPU 병목 → /proc/loadavg, top -bn1, slow query 동시 수집
- Too many connections → SHOW PROCESSLIST, SHOW STATUS LIKE 'Threads_connected', max_connections 대비 비율
- 복제 지연 → SHOW REPLICA STATUS의 Seconds_Behind_Source, relay log 위치 등
주의사항
장애 상황에서 1차 실행이 장애를 악화시킬 수 있으므로, 1차 실행 때 DB 상태 수집 작업은 빠르고 가벼워야 함
장애 직후 1차 수집 한번만 vs 주기적 수집
한번만 수집의 문제점: 장애 직후 1차 실행 시 DB 접속 자체가 불가능해 DB 상태 정보 수집에 실패 가능
=> 주기적 수집은 장애 시점에 DB 접속이 안돼도 직전까지 수집된 데이터가 남아있어 타임라인의 품질이 올라감
의문점
- 별도 데몬/cron 운영 부담: 초 or 분 단위의 cron을 실행하는 데 필요한 자원, 관리에 드는 시간이 얼마인가?
- 수집 주기: 수집 주기는 몇초 or 몇분으로 할 것인가?
- 수집 데이터 적재량: 최근 1시간치만을 보존 기간으로 제한한다면, 데이터가 얼마나 적재되나?
- 수집 작업이 주는 DB 부하: show status나 show processlist 등의 명령이 DB에 얼마나 많은 부하를 주는가?
주기적 수집 1안
주기적 수집 2안: kafka 도입

기존에는 장애 정상화 이후 스크립트를 실행하면
'로그 에이전트(error log, journalctl 수집)' -> '타임라인 생성기' 부분만 존재했음
이 아이디어의 경우, kafka 사용의 유용성을 위해 타임라인 생성기 이외에도 '알림', '대시보드' 등 여러 시스템이 동시에 데이터를 소비한다고 가정함
=> 프로젝트의 사이즈가 훨씬 커짐
장점
- 수집 주기의 유연성: 수집 주기를 고정된 시간(1분)으로 정하지 않고, 주기적 폴링과 이벤트 기반 발행(스레드 수가 임계치의 80%를 넘는 순간 발행)을 혼합하는 방식 사용 가능
- 데이터 보존기간 설정: retention을 설정해, 토픽에 데이터가 일정 기간 동안 살아있도록 하고 필요없는 데이터는 제거하도록 함
- 그 외: producer와 consumer의 완전한 분리(kafka pub/sub 구조의 일반적인 특징) - 수집 측은 소비자가 누군지 몰라도 메시지를 보내기만 하면 됨, 나중에 새로운 소비자를 추가
단점
- 소규모 환경에서는 과도한 설계
- 인프라 복잡도 증가: kafka 클러스터 운영에 따른 토픽 관리, 모니터링(모니터링 시스템을 위한 모니터링) 등 필요
- kafka 자체의 장애 시 수집이 중단됨: 장애 대응 필요(kafka 장애 시 타임라인 수집은 기존 스크립트로 대체 등)
구현 시 고려할 점
- 토픽 설계: DB 인스턴스별로 파티션을 나눠 특정 인스턴스의 데이터를 시간순으로 조회하기 용이하도록 구성
- 적절한 retention(보존 기간) 설정: 장애 발생 전 24시간을 분석하고 싶다면 retention을 최소 24시간으로 설정
- 에이전트 설계: 수집 단의 에이전트가 DB 위에서 돌아가므로, kafka 프로듀셔의 메모리 사용량과 네트워크 부하를 통제해 경량화하는 것이 중요
- 메시지 저장 포맷: 처음부터 스키마를 잘 설계해야 뒷 단의 소비자가 데이터를 잘 가져가 정제해 사용할 수 있음
'인턴' 카테고리의 다른 글
| [과제5-7] DB 상태 수집 프로그램 재설계(C to Python 변환) 프로젝트 최종 발표 (0) | 2026.04.09 |
|---|---|
| [장애 이력 작성 도구] 발표 이후 고도화2 - 실행 명령어 옵션 --replica 제거 (0) | 2026.03.20 |
| [스터디3] MySQL 스터디 - 클러스터드 vs 논클러스터드 인덱스 2차 실험 (0) | 2026.03.20 |
| [장애 이력 자동 작성 도구] 발표 이후 고도화 - 장애 감지 로직 수정 (0) | 2026.03.19 |
| [스터디4] 개발자를 위한 레디스 (0) | 2026.03.18 |


